5 minutes
Fast SQL Server Imports with R
Writing large datasets to SQL Server can be very slow using the DBI package with an odbc connection. The issue with writing data is that individual INSERT statements are generated for each row of data. I’ve also had issues with remote connections that can make large writes to SQL Server take a very long time. SQL Server Management Studio does provide a GUI interface to import data that is much more efficient. For those that want to include the data import in their reproducible R workflows there are a couple of options.
BULK INSERT statements
The fastest method is to use BULK INSERT statements with the data written to a file on the machine where the SQL Server resides. This requires that you have access/permissions to transfer the file to the remote host’s local filesystem and the server can access that location.
We can make use of the DBI::sqlCreateTable to generate the table schema
and make some edits to it (optional) and then create the table for import.
library(DBI)
library(data.table)
library(nycflights13)
data("flights")
set.seed(88)
con <- ANSI()
flights <- flights[sample.int(nrow(flights), 1000000, replace = TRUE),]
fwrite('flights.csv')
# Take a guess at the table schema and write it
dbCreateTable(conn = con, name = 'dbo.TableName', fields = flights)c
A handy trick for generating code that you can edit for the schema and submit
with dbExecute is
writeClipboard(sqlCreateTable(con = con, table = SQL('dbo.TableName'),
fields = flights, row.names = FALSE))
For this example, the file is written to a temporary file with field separators and line endings that match the defaults for BULK INSERT. The order of the data columns in the file needs to match the order of columns in the table created.
# Create a temporary file
folder <- '//server/folder'
tmp <- tempfile(tmpdir = folder, fileext = '.txt')
# Headers are not accepted and BULK INSERT assumes you have the data columns
# in the same order as the table columns
fwrite(flights, tmp, sep = '\t', col.names = FALSE)
# Execute Bulk Insert on the MS SQL Server
dbExecute(con,
sqlInterpolate(con,
"
BULK INSERT dbo.TableName
FROM ?tmp
WITH
(
FIELDTERMINATOR ='\t'
, ROWTERMINATOR = '\n'
)", tmp = tmp)
)
bcp Utility
If you are not able to write the file to a location that the SQL Server instance can access with the BULK INSERT statement, you can use the bulk copy program utility (bcp). bcp does not require knowledge of T-SQL and offers a few more options to control the import process.
The full documentation is provided here: bcp Utility.
bcp will need to be installed on your local machine and added to the system path. Using that same temp file and schema that was generated earlier, you can invoke bcp CLI with:
system2('bcp', args = c('schema.TableName',
'in', tmp,
'-S', 'server',
'-d', 'database',
'-t',
'-r', '\n',
'-c',
'-T'))
The documentation for the arguments can be found in the aformentioned documentation. This example uses trusted authentication, ‘\t’ as the column/field separators and ‘\n’ as the row/line terminators.
bcputility
The bcputility provides a wrapper to the bcp command line program that has
some useful argument defaults, and abstracts away the file I/O and
schema creation. We can now have fast writes of large imports with one line
of code.
library(bcputility)
bcpImport(flights, server = server, database = database, table = 'flights1')
We can customize how data is passed with the batchsize and packetsize
arguments.
bcpImport(flights, server = server, database = database, table = 'flights1',
batchsize = 50000, packetsize = 4096*2)
Arguments can be passed to system2 with ... so we can check the
results of the import process.
bcpImport(flights, server = server, database = database, table = 'flights1',
batchsize = 50000, packetsize = 4096*2,
stdout = FALSE, # suppress printing to console
stderr = 'import-flights-error.txt' # write errors to file
)
If you need to change the default terminators, because the data includes tabs or newlines:
bcpImport(flights, server = server, database = database, table = 'flights1',
batchsize = 50000, packetsize = 4096*2,
stdout = FALSE, # suppress printing to console
stderr = 'import-flights-error.txt' # write errors to file
fieldterminator = '|',
rowterminator = '\r\n|\r\n'
)
You can switch to sql authentication which you might need if writing to a database on Azure or trusted connections are not allowed.
bcpImport(flights, server = server, database = database, table = 'flights1',
batchsize = 50000, packetsize = 4096*2,
stdout = FALSE, # suppress printing to console
stderr = 'import-flights-error.txt' # write errors to file
fieldterminator = '|',
rowterminator = '\r\n|\r\n'
username = 'myname',
password = 'mypassword'
)
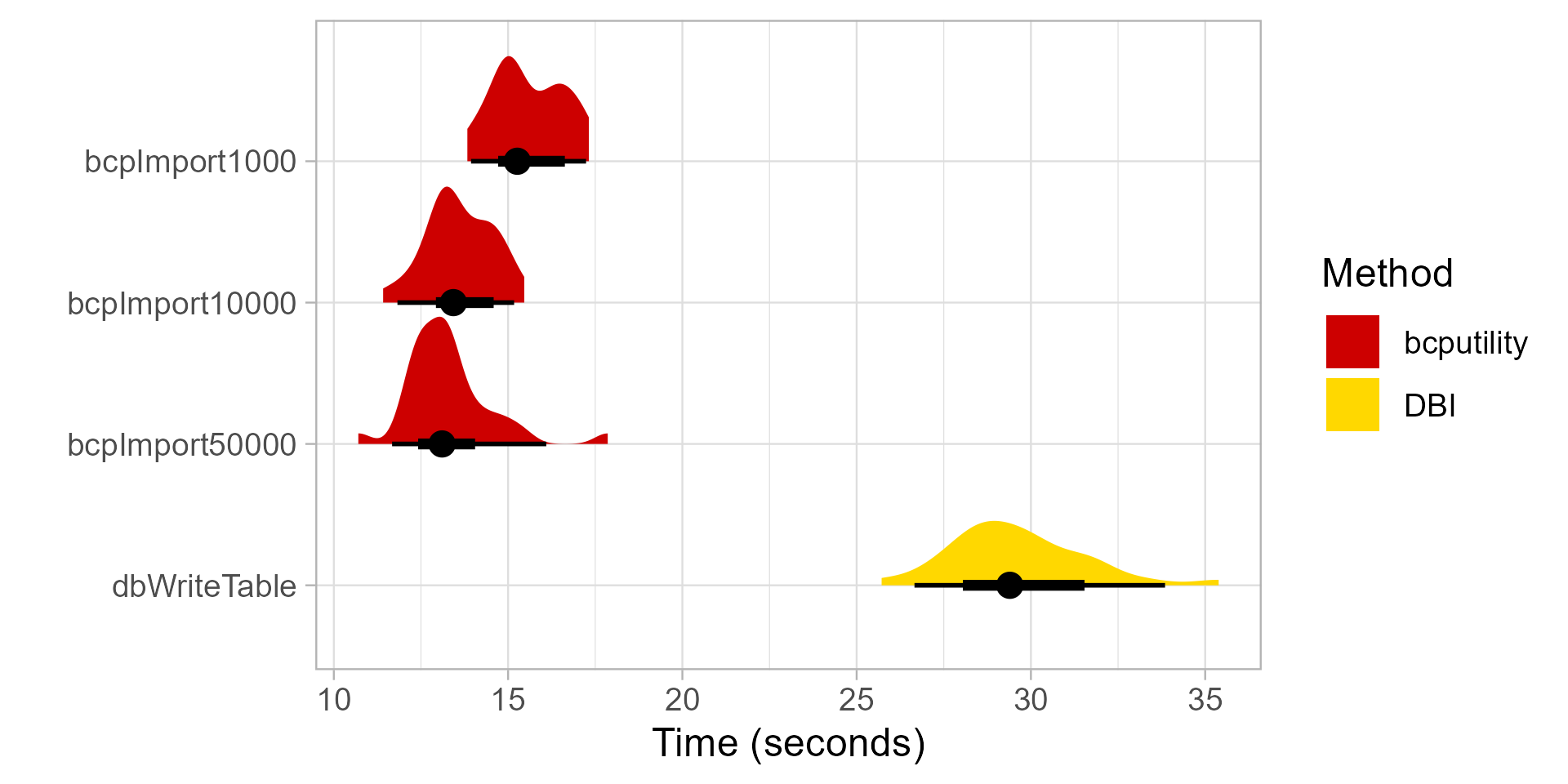
Benchmarks
Benchmarks were performed with a local installation of SQL Server Express.
library(DBI)
library(data.table)
library(nycflights13)
data("flights")
set.seed(82)
flights <- flights[sample.int(nrow(flights), 1000000, replace = TRUE),]
server <- 'localhost\\SQLEXPRESS'
database <- 'Main'
con <- DBI::dbConnect(odbc::odbc(),
Driver = "SQL Server",
Server = server,
Database = database)
results <- microbenchmark::microbenchmark(
bcpImport1000 = {
bcpImport(flights,
server = server,
database = database,
table = 'flights1',
overwrite = TRUE,
stdout = FALSE)
},
bcpImport10000 = {
bcpImport(flights,
server = server,
database = database,
table = 'flights2',
overwrite = TRUE,
stdout = FALSE,
batchsize = 10000)
},
bcpImport50000 = {
bcpImport(flights,
server = server,
database = database,
table = 'flights3',
overwrite = TRUE,
stdout = FALSE,
batchsize = 50000)
},
dbWriteTable = {
DBI::dbWriteTable(con, name = 'flights4', flights, overwrite = TRUE)
},
times = 30L
)